近期,OpenAI Translator 和 NextChat 相继支持了 Ollama 本地运行的大型语言模型,这对「新手上路」的爱好者来说,又多了一种新玩法。
Ollama 是一款开创性的人工智能(AI)和机器学习(ML)工具平台,它极大地简化了 AI 模型的开发和使用过程。
在众多 AI 工具中,Ollama 凭借以下几个关键优势脱颖而出,这些特性不仅彰显了其独特性,更解决了 AI 开发者和爱好者们最常遇到的难题:
- 自动硬件加速:Ollama 能自动识别并充分利用 Windows 系统中的最优硬件资源。无论你是配备了 NVIDIA GPU、AMD GPU,还是 CPU 支持 AVX、AVX2 这样先进的指令集,Ollama 都能实现针对性优化,确保 AI 模型更加高效地运行。有了它,就不用再头疼于复杂的硬件配置问题了,你可以将更多的时间和精力都集中在项目本身。
- 无需虚拟化:在进行 AI 开发时,以往常常需要搭建虚拟机或配置复杂的软件环境。而 Ollama 让这一切都不再成为阻碍,直接就能开始 AI 项目的开发,整个流程变得简单快捷。对于想尝试 AI 技术的个人或组织来说,这种便捷性降低了很多门槛。
- 接入完整的 Ollama 模型库:Ollama 为用户提供了丰富的 AI 模型库,包括像 LLaVA 这样的先进图像识别模型和 Google 最新推出的 Gemma 模型等。拥有这样一个全面的「武器库」,我们可以轻松尝试和应用各种开源模型,而不用自己费时费力地去搜寻整合。无论你想进行文本分析、图像处理,还是其他 AI 任务,Ollama 的模型库都能提供强有力的支持。
- Ollama 的常驻 API:在软件互联的今天,将 AI 功能整合到自己的应用中极具价值。Ollama 的常驻 API 大大简化了这一过程,它会在后台默默运行,随时准备将强大的 AI 功能与你的项目无缝对接,而无需额外的复杂设置。有了它,Ollama 丰富的 AI 能力会随时待命,能自然而然地融入你的开发流程,进一步提升工作效率。
Ollama 通过这些精心设计的功能特性,不仅解决了 AI 开发中的常见难题,还让更多的人能够轻松地接触和应用先进的 AI 技术,极大地扩展了 AI 的应用前景。
在 Windows 上使用 Ollama
欢迎迈入 AI 和 ML 的新时代!接下来,我们将带你完成上手的每一步,还会提供一些实用的代码和命令示例,确保你一路畅通。
步骤 1:下载和安装
1访问 Ollama Windows Preview 页面,下载OllamaSetup.exe安装程序。
2双击文件,点击「Install」开始安装。
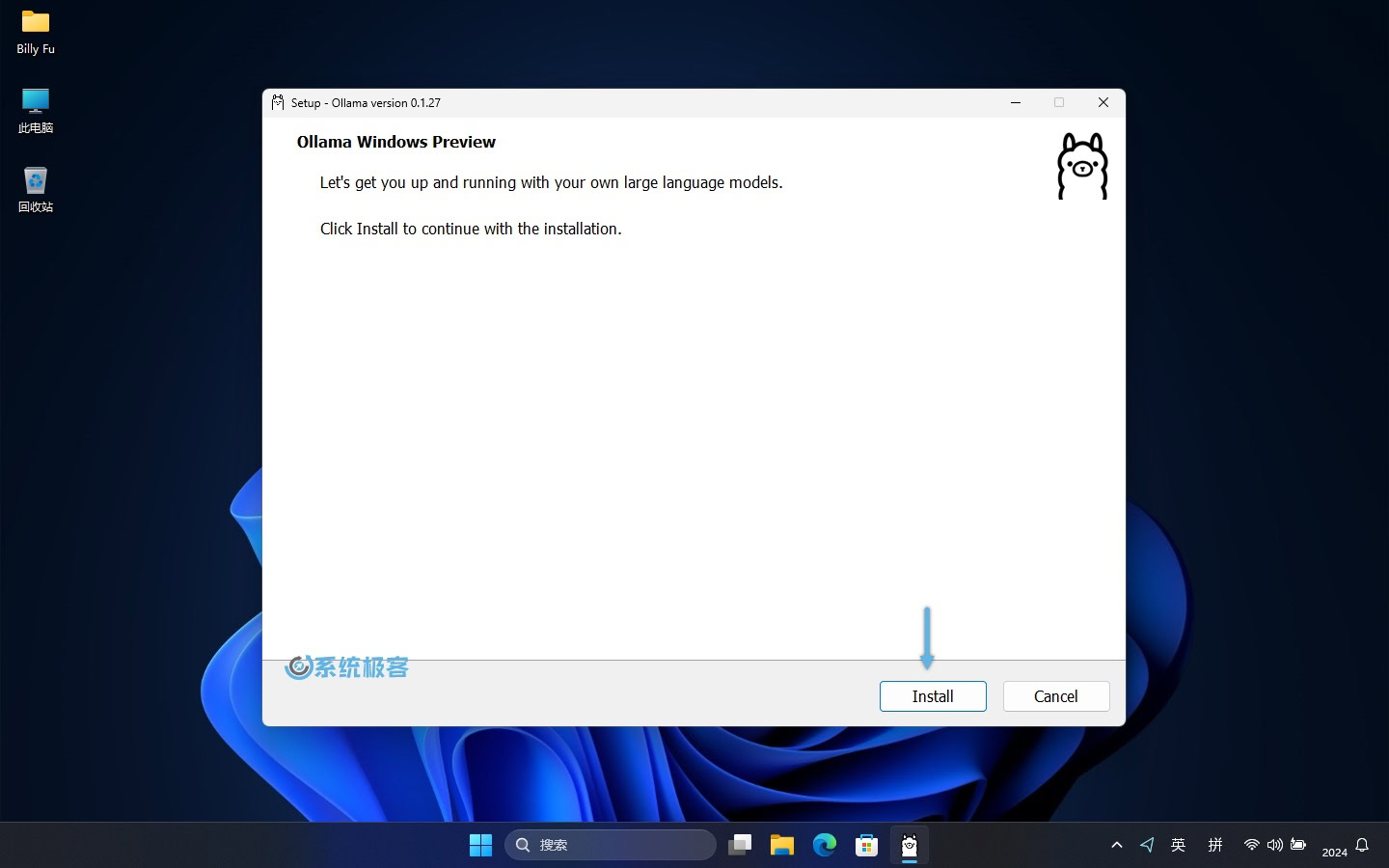
3安装完成之后,就可以开始在 Windows 上使用 Ollama 了,是不是非常简单。
步骤 2:启动 Ollama 并获取模型
要启动 Ollama 并从模型库中获取开源 AI 模型,请按以下步骤操作:
1在「开始」菜单中点击 Ollama 图标,运行后会在任务栏托盘中驻留一个图标。
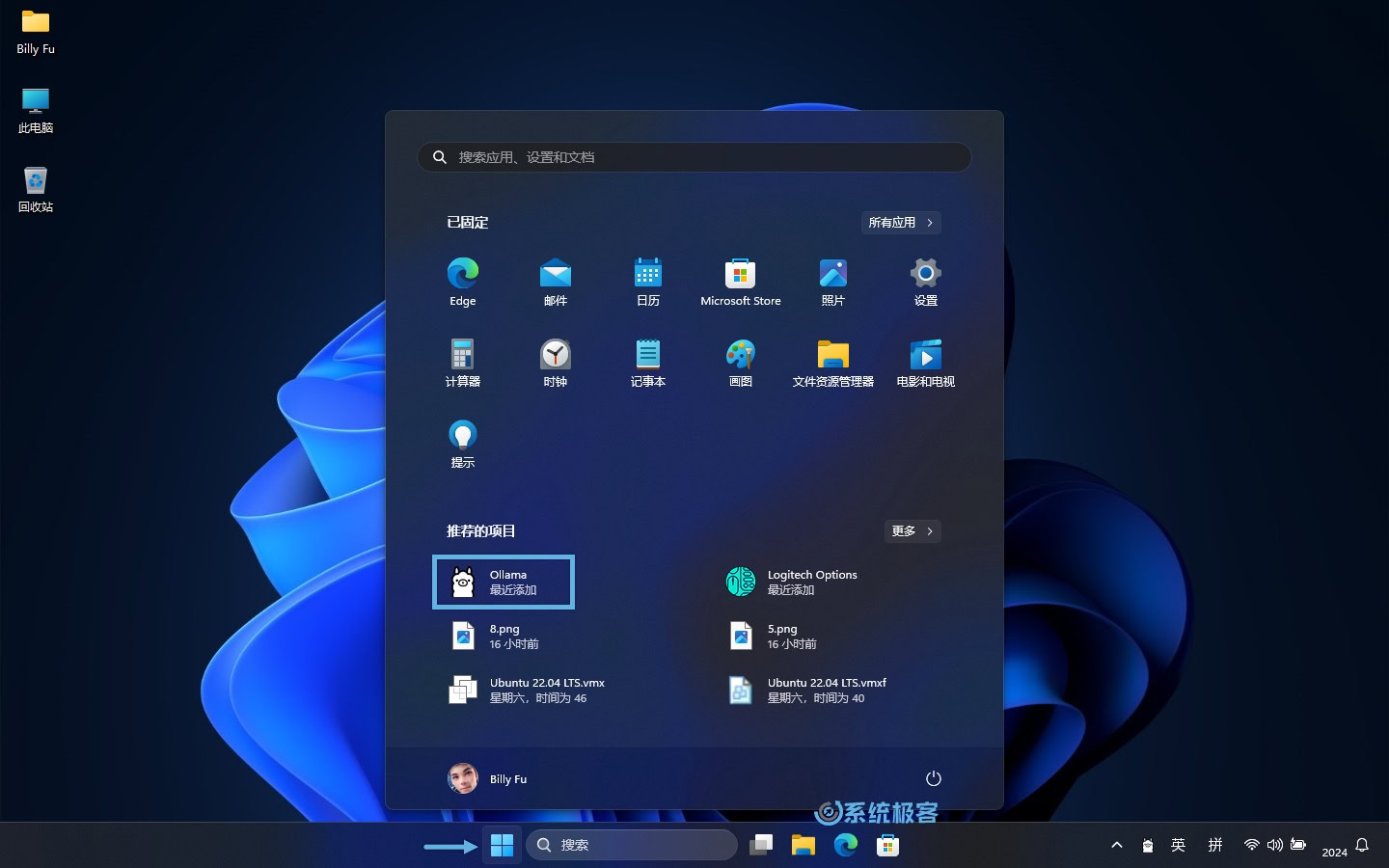
2右键点击任务栏图标,选择「View log」打开命令行窗口。
3执行以下命令来运行 Ollama,并加载模型:
ollama run [modelname]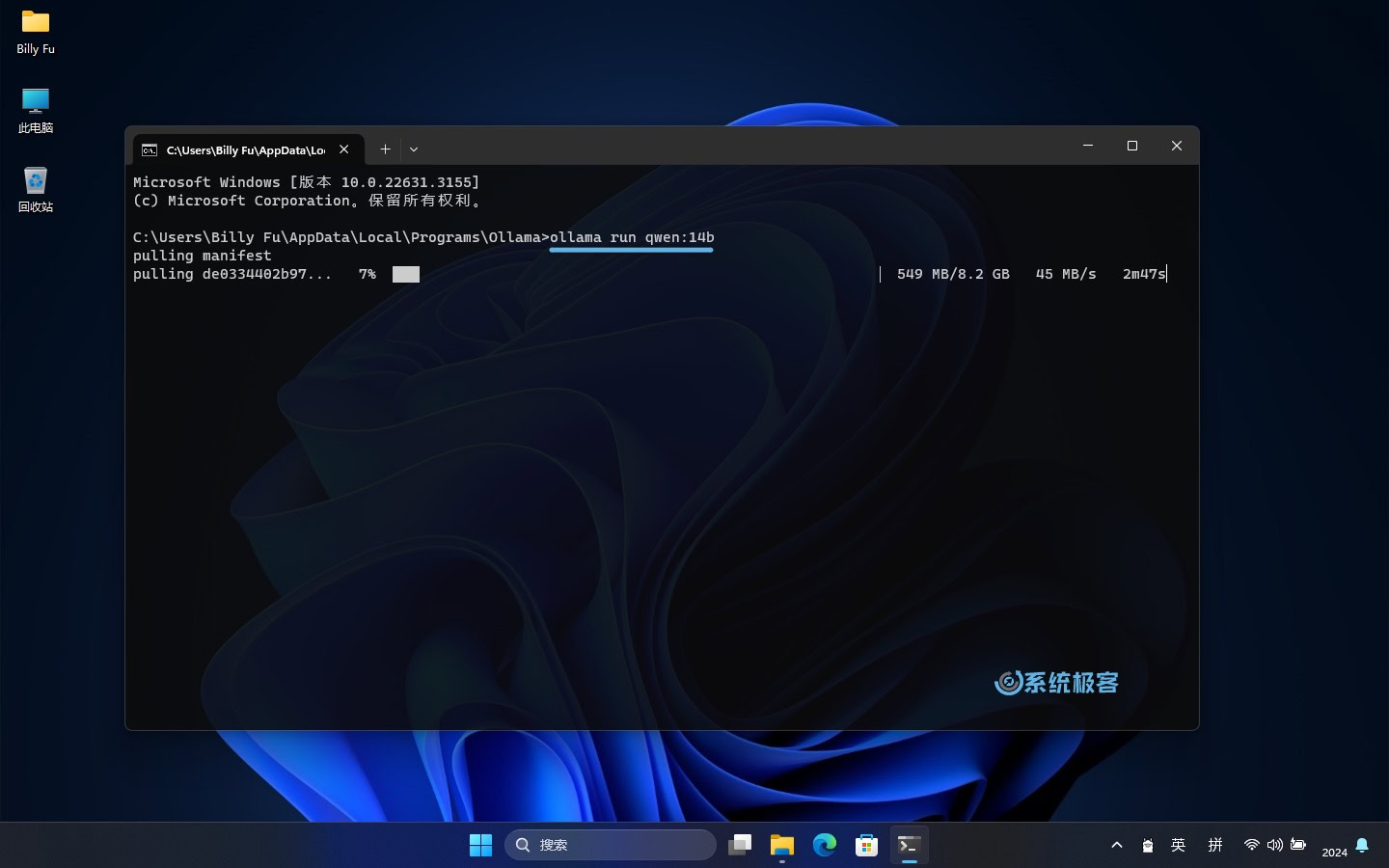
执行以上命令后,Ollama 将开始初始化,并自动从 Ollama 模型库中拉取并加载所选模型。一旦准备就绪,就可以向它发送指令,它会利用所选模型来进行理解和回应。
记得将modelname名称换成要运行的模型名称,常用的有:
| 模型 | 参数 | 大小 | 安装命令 | 发布组织 |
|---|---|---|---|---|
| Code Llama | 7B | 3.8GB | ollama run codellama | Meta |
| Llama 3 8B | 8B | 4.7GB | ollama run llama3:8b | Meta |
| Llama 3 70B | 70B | 20GB | ollama run llama3:70b | Meta |
| Llama 2 | 7B | 3.8GB | ollama run llama2 | Meta |
| Llama 2 13B | 13B | 7.3GB | ollama run llama2:13b | Meta |
| Llama 2 70B | 70B | 39GB | ollama run llama2:70b | Meta |
| Mistral | 7B | 4.1GB | ollama run mistral | Mistral AI |
| mixtral | 8x7b | 26GB | ollama run mixtral:8x7b | Mistral AI |
| Phi-3 Mini | 3.8B | 2.3GB | ollama run phi3:3.8b | Microsoft Research |
| LLaVA | 7B | 4.7GB | ollama run llava:7b | Microsoft Research Columbia University Wisconsin |
| Gemma 2B | 2B | 1.4GB | ollama run gemma:2b | |
| Gemma 7B | 7B | 4.8GB | ollama run gemma:7b | |
| Qwen 4B | 4B | 2.3GB | ollama run qwen:4b | 阿里巴巴 |
| Qwen 7B | 7B | 4.5GB | ollama run qwen:7b | 阿里巴巴 |
| Qwen 14B | 14B | 8.2GB | ollama run qwen:14b | 阿里巴巴 |
运行 7B 至少需要 8GB 内存,运行 13B 至少需要 16GB 内存。
步骤 3:使用模型
如前所述,Ollama 支持通过各种各样的开源模型来完成不同的任务,下面就来看看怎么使用。
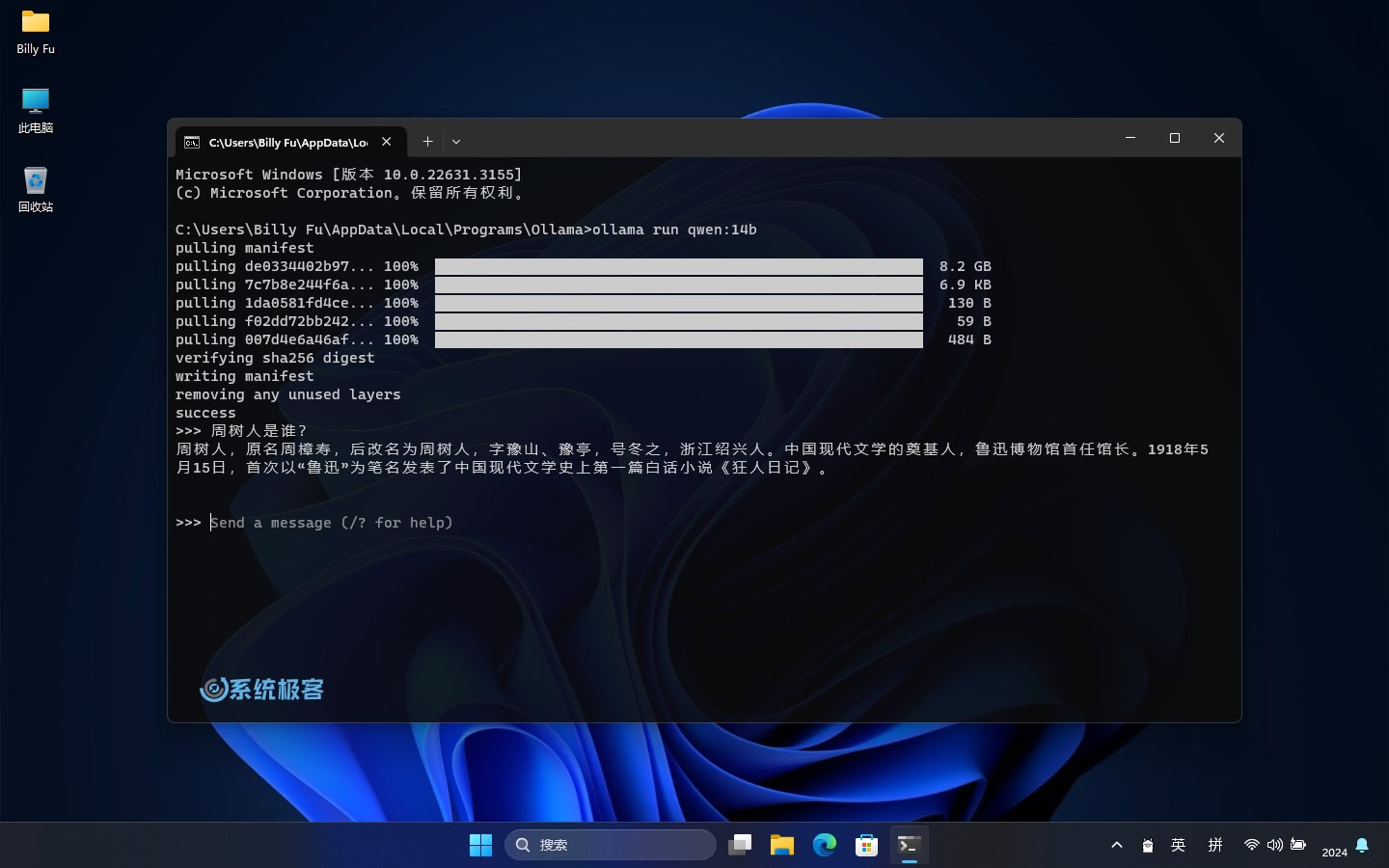
- 基于文本的模型:加载好文本模型后,就可以直接在命令行里输入文字开始与模型「对话」。例如,阿里的 Qwen(通义千问):
- 基于图像的模型:如果你想使用图像处理模型,如 LLaVA 1.6,可以使用以下命令来加载该模型:
ollama run llava1.6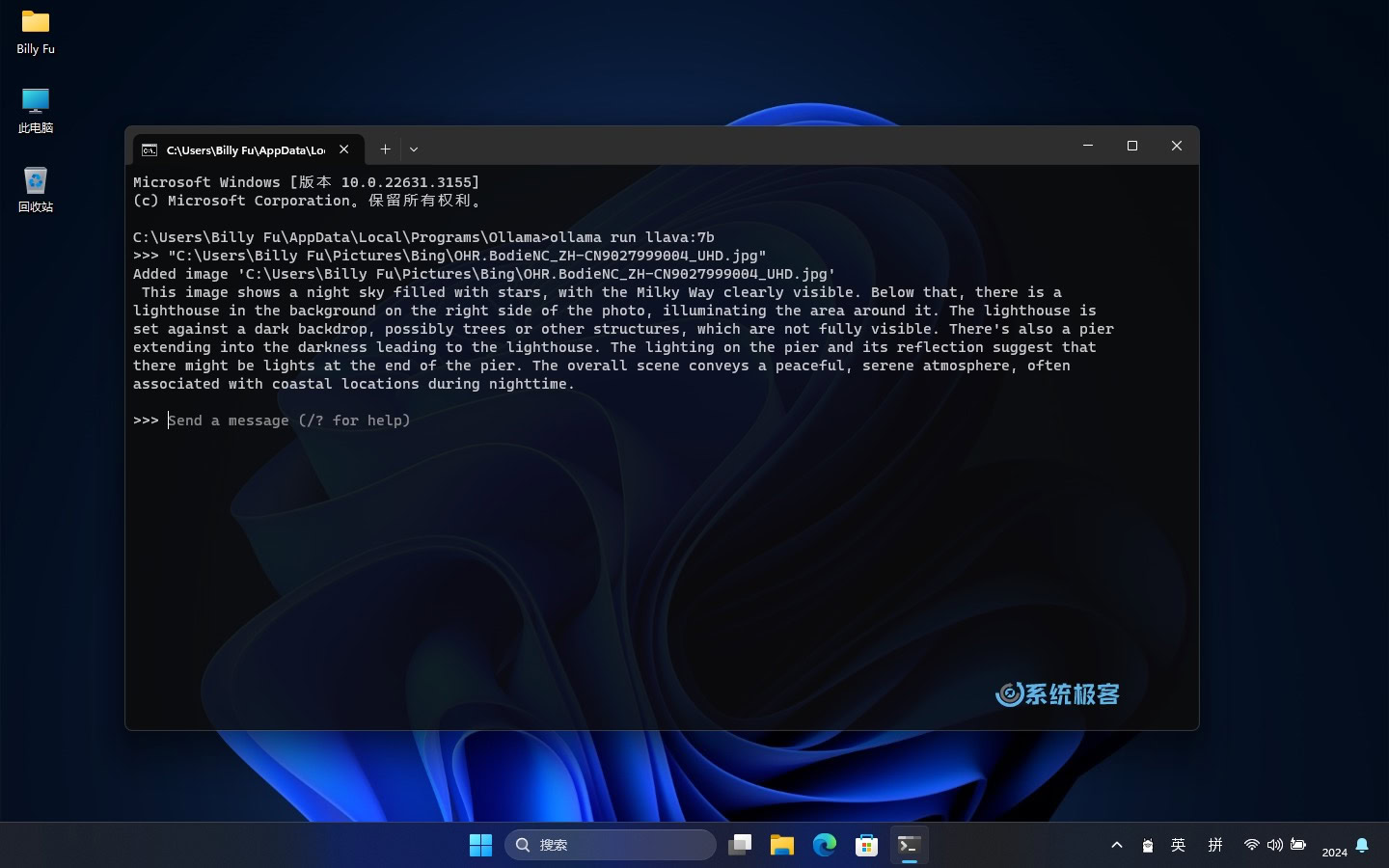
Ollama 会使用你选择的模型来分析这张图片,并给你一些结果,比如图片的内容和分类,图片是否有修改,或者其他的分析等等(取决于所使用的模型)。
步骤 4:连接到 Ollama API
我们不可能只通过命令行来使用,将应用程序连接到 Ollama API 是一个非常重要的步骤。这样就可以把 AI 的功能整合到自己的软件里,或者在 OpenAI Translator 和 NextChat 这类的前端工具中进行调用。
以下是如何连接和使用 Ollama API 的步骤:
- 默认地址和端口:Ollama API 的默认地址是
http://localhost:11434,可以在安装 Ollama 的系统中直接调用。 - 修改 API 的侦听地址和端口:如果要在网络中提供服务,可以修改 API 的侦听地址和端口。
1、右击点击任务栏图标,选择「Quit Ollama」退出后台运行。
2、使用Windows + R快捷键打开「运行」对话框,输出以下命令,然后按Ctrl + Shift + Enter以管理员权限启动「环境变量」。
C:\Windows\system32\rundll32.exe sysdm.cpl, EditEnvironmentVariables3、要更改侦听地址和端口,可以添加以下环境变量:
- 变量名:
OLLAMA_HOST - 变量值(端口):
:8000
只填写端口号可以同时侦听(所有) IPv4 和 IPv6 的:8000端口。
要使用 IPv6,需要 Ollama 0.0.20 或更新版本。
4因浏览器安全限制,如果要在 NextChat 和 LoboChat 等面板中调用 API ,你需要为 Ollama 进行跨域配置后方可正常使用:
- 变量名:
OLLAMA_ORIGINS - 变量值:
*
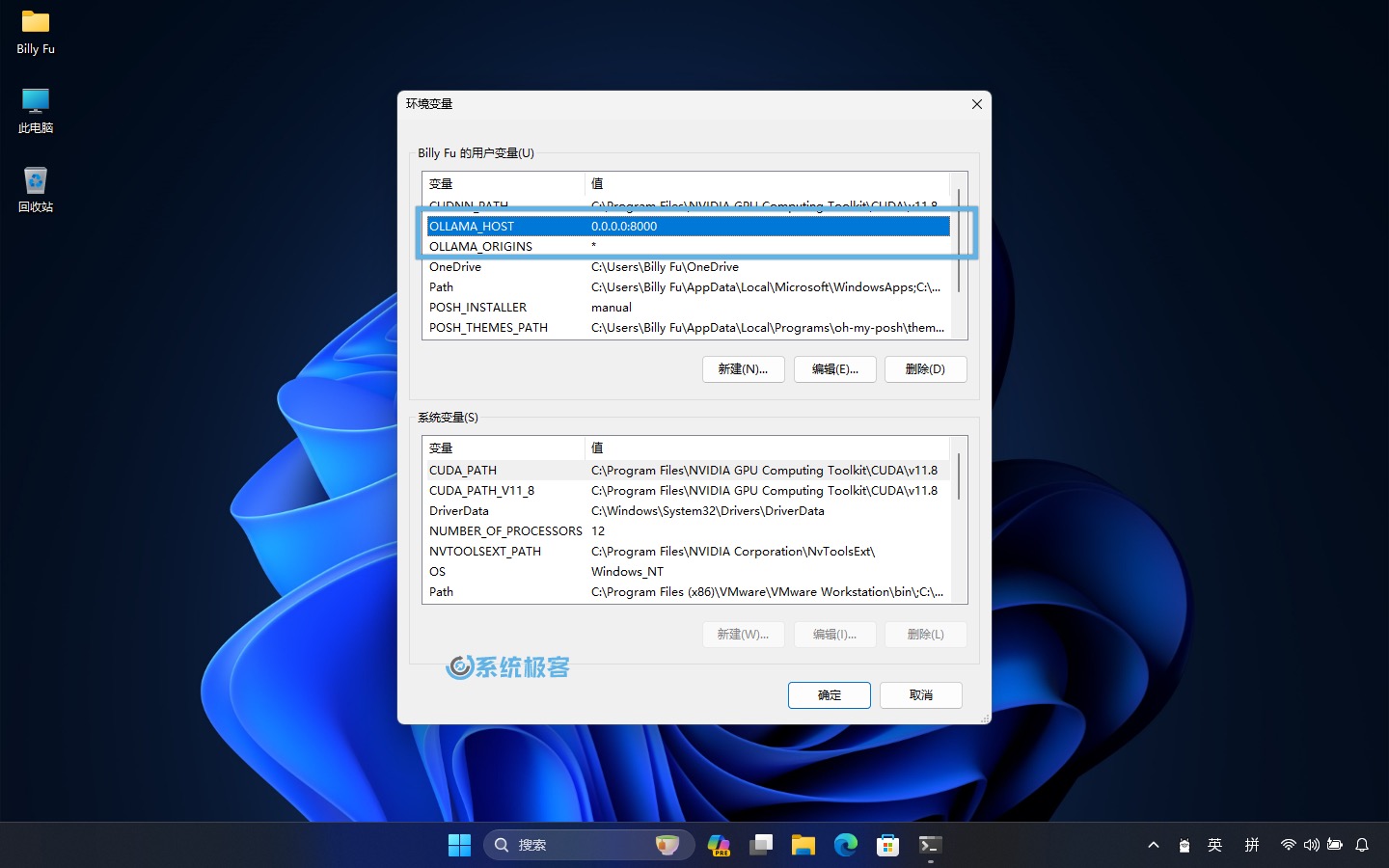
如果安装了多个模型,还可以通过OLLAMA_MODELS变量名来指定默认模型。
5、更改完之后,重新运行 Ollama。然后在浏览器中测试访问,验证更改是否成功。
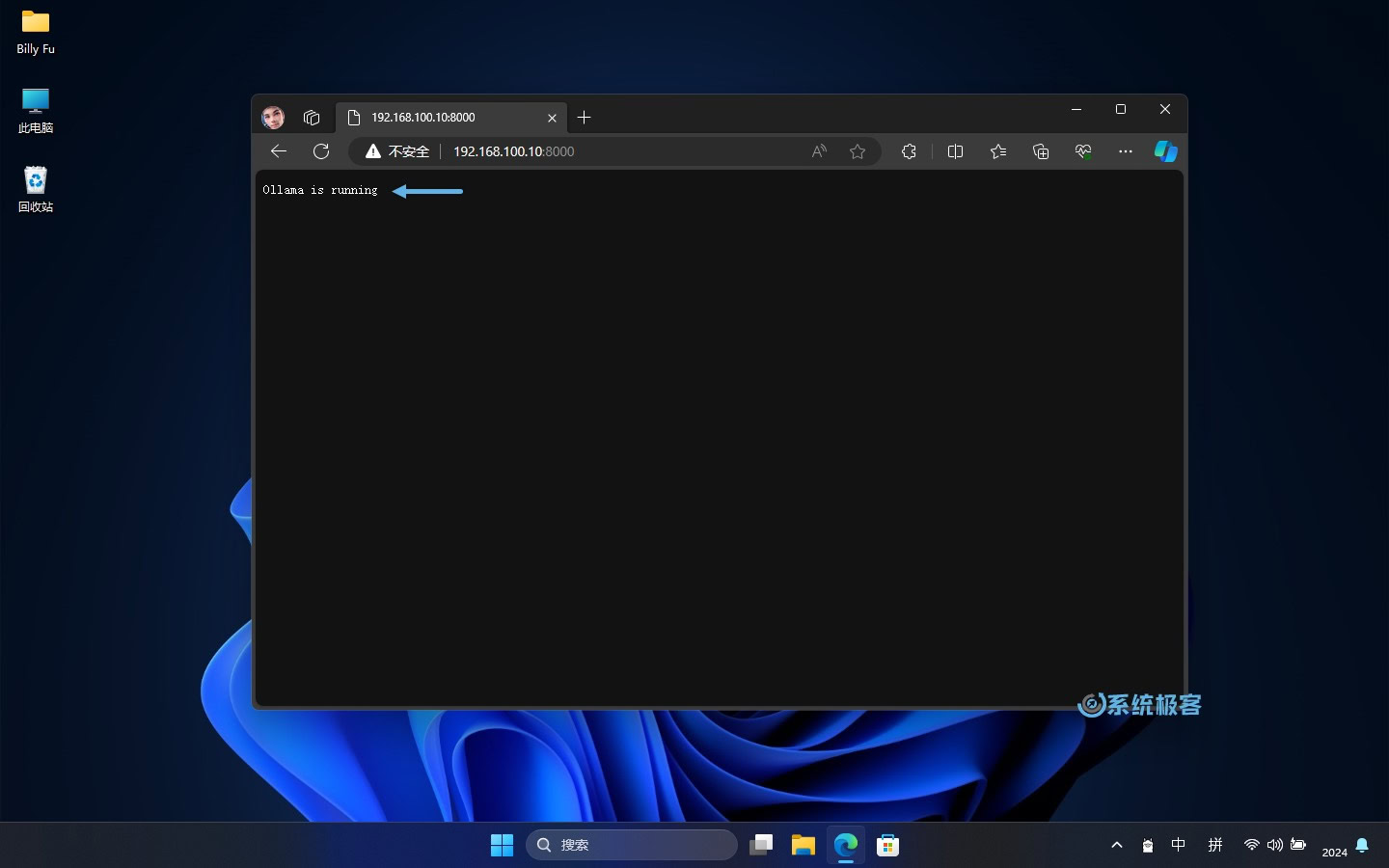
6、示例 API 调用: 要使用 Ollama API,可以在自己的程序里发送 HTTP 请求。下面是在「终端」里使用curl命令给 Gemma 模型发送文字提示的例子:
curl http://192.168.100.10:8000/api/generate -d '{
"model": "gemma:7b",
"prompt": "天空为什么是蓝色的?"
}'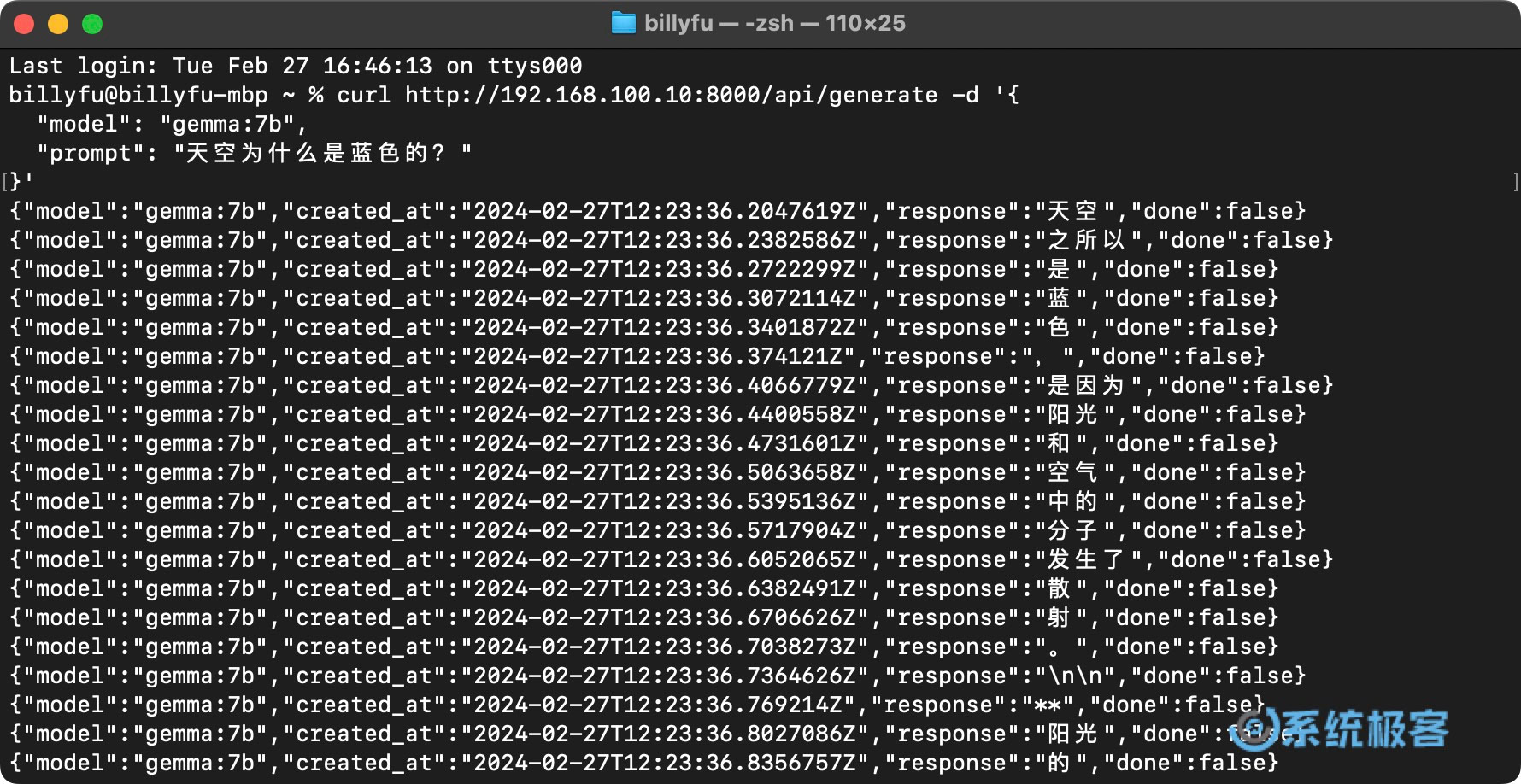
返回响应的格式,目前只支持 Json 格式。
Ollama 的常用命令有:
# 查看 Ollama 版本
ollama -v
# 查看已安装的模型
ollama list
# 删除指定模型
ollama rm [modelname]
# 模型存储路径
# C:\Users\<username>\.ollama\models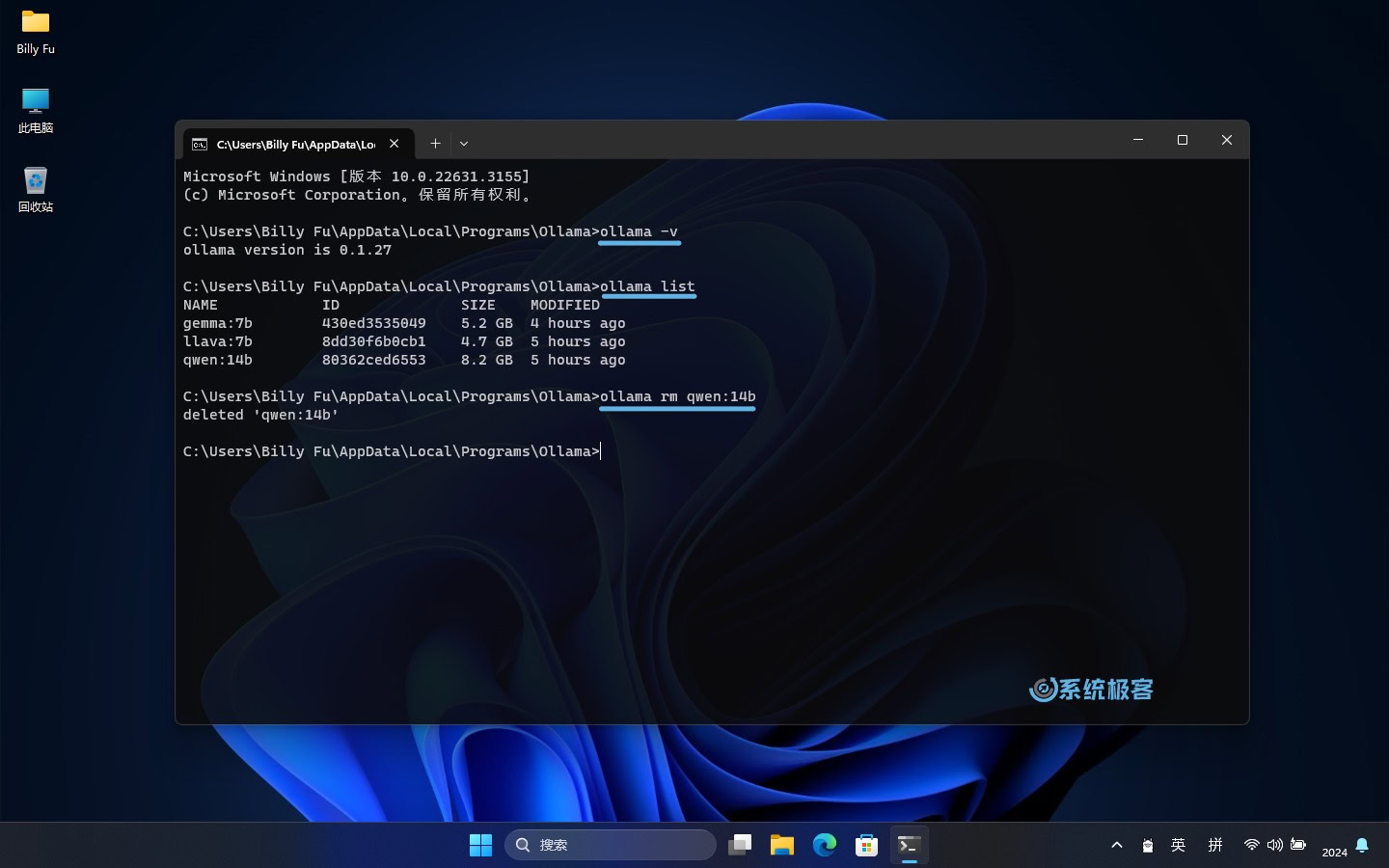
按照上述步骤,并参考命令示例,你可以在 Windows 上尽情体验 Ollama 的强大功能。不管是在命令行中直接下达指令,通过 API 将 AI 模型集成到你的软件当中,还是通过前端套壳,Ollama 的大门都已经为你敞开。
本地搭建测试:UUZAI
本文摘录自https://www.sysgeek.cn/ollama-on-windows/